
Hello Potato World
[포테이토 스터디] Permutation Feature Importance 본문
⋆ 。 ˚ ☁︎ ˚ 。 ⋆ 。 ˚ ☽ ˚ 。 ⋆
[XAI study_ Interpretable Machine Learning]
5.5 Permutation Feature Importance
특성 값을 섞은 후에 모델의 prediction error를 측정하여 구하는 방식
- Important Feature
feature의 값들을 섞었을 때 모델의 prediction error가 증가하는 경우
모델의 prediction이 특성에 의존적
- Unimportant Feature
feature의 값들을 섞었을 때 모델의 prediction error가 변하지 않는 경우
모델의 prediction이 특성에 무관
Algorithm
The Permutation feature importance algorithm based on Fisher, Rudin, and Dominici(2018):

Training or Test Data?
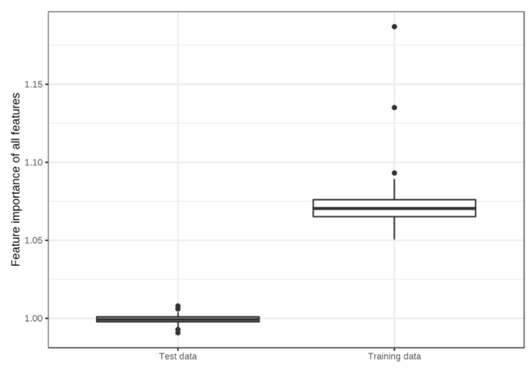
무관한 50개의 특성이 존재하는 Training data에 과적합 된 SVM 모델
- Training Data의 MAE : 0.29
- Test Data의 MAE : 0.82
Test data를 사용하여 모델의 성능 반영 vs Training data만을 사용하여 feature의 영향력 반영
더보기
- Test Data
- Trainig data를 기반으로 추정한 모델의 오차는 신뢰도 낮음
- Feature Importance는 모델의 오차에 의존적
- Training data를 기반으로 계산한 Feature Importance는 신뢰도 낮음
- Training Data
Feature Importance는 모델의 오차 변화에만 의존적이여서 model의 성능은 반영하지 못함
중요하지 않은 특성을 중요하다고 판단 가능
Training vs Test : 현재까지 정답 없음
Example Results

자전거 수를 예측하는 SVM의 Permutation Feature Importance
- 가장 중요한 특징 : Temp
- 가장 중요하지 않은 특징 : Holiday
Advantages
- Error rate대신 Error difference를 사용하면 특성 중요도 측정 단위가 다른 문제에도 적용 가능
- 다른 특성과의 모든 상호작용 자동적으로 고려
특성의 값을 섞으면 다른 특성과의 interaction도 깨짐 - 모델을 재학습할 필요 없음
Disadvantages
- Training Data vs Test Data 불명확
- 오델의 Error로만 계산하기 때문에 모델의 robustness 등을 반영하지 못함
- True Outcome 필요
- Outlier Data에 편향될 수 있음
- 상호 연관된 특성을 추가하면 Importance가 분할되어 결과가 혼동될 수 있음.
(ex) Probability of rain => "temperature of 8:00AM" & "temperature of 9:00AM"
References
[1] Interpretable Machine Learning, Christoph Molnar
감자같은 학부생이 일부만 정리하는 리뷰입니다. 더 궁금한 점은 댓글로 물어봐주세요🥔
'Study > XAI' 카테고리의 다른 글
| [포테이토 스터디] Influential Instances (0) | 2021.06.22 |
|---|---|
| [포테이토 스터디] Prototypes and Criticisms (0) | 2021.06.22 |
| [포테이토 스터디] Local Surrogate(LIME) (0) | 2021.05.24 |
| [포테이토 스터디] Global Surrogate (1) | 2021.05.24 |
| [포테이토 스터디] Feature Interaction (0) | 2021.05.22 |
'Study/XAI' Related Articles
more




Comments