
Hello Potato World
[포테이토 논문 리뷰] YOLO9000: Better, Faster, Stronger(&Yolov2) 본문
[포테이토 논문 리뷰] YOLO9000: Better, Faster, Stronger(&Yolov2)
Heosuab 2020. 12. 4. 04:16
⋆ 。 ˚ ☁︎ ˚ 。 ⋆ 。 ˚ ☽ ˚ 。 ⋆
[Object Detection paper review]
YOLO9000
이 논문에서는 YOLO의 mAP와 FPS를 개선시킨 YOLOv2와, object categories를 약 9000종류 이상으로 넓게 확장시킨 YOLO9000 모델에 대해 설명하고 있다. 사실 논문 제일 첫부분에서 언급한 주요 아이디어에 대한 내용은 끝부분에 나와있어서 중간에 잠깐 혼란스러웠던 것 같다(?)
YOLOv1에서 개선된 부분들을 총 3가지 section으로 나눠 설명하고 있다.
- Better : mAP 개선 (약 13.4%↑, 416*416input 기준)
- Faster : FPS 개선 (약 22%↑)
- Stronger : object categories를 9000개 이상으로 끌어올린 방법
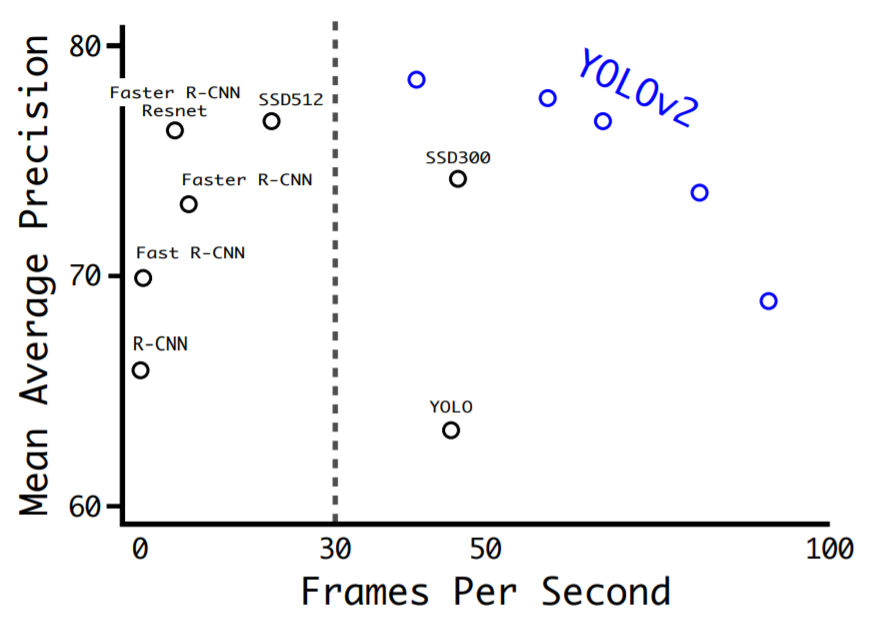
Better
YOLOv1의 한계점을 언급하면서 mAP를 끌어올리기 위해 집중한 2가지 해결점을 언급하고 있다.
- Fast R-CNN과 비교해 보았을 때, YOLOv1은 localization error가 크다.
- Recall이 상대적으로 더 낮게 나오는 경향을 보인다.
- Batch Normalization
Batch Normalization은 Neural Network의 layer 내에서 batch의 분포를 정규화해서 안정적으로 만들어주는 reaularization 방법이다. 기존 YOLOv1 모델의 모든 convolution layer에 배치 정규화를 사용하고 dropout을 제거해서 mAP를 2%정도 향상시켰다.
- High Resolution Classifier
기존 YOLOv1는 224*224의 input image에 맞게 pre-trained network를 사용했는데 detection에서는 448*448의 input을 사용했기 때문에 resolution의 불일치 문제가 있었다. (왜 이렇게 했을지는 나도 궁금하다..) 이 문제를 언급하면서 ImageNet을 사용하여 10epochs로 448*448의 resolution에 맞게 한번 더 fine-tuning을 거쳐서(학습시켜서) mAP를 4% 향상시켰다.
- Convolutional With Anchor Boxes
FC layer를 사용해서 bounding box의 좌표값을 예측하는 것보다, feature map 에서 각 grid cell마다 anchor box를 사용하여 offset을 예측하는 방식이 더 간단하기 때문에(Faster R-CNN처럼) YOLOv1의 fc layer를 제거해서 전부 Convolutional Network로 만들고 anchor box를 도입했다.

또 YOLOv1에서는 448*448의 input image를 사용했지만 YOLOv2에서는 416*416로 수정했다. Convolution layer를 전부 거치고 나면 resolution이 총 32배로 줄어들게 되는데 448*448을 사용할 경우 14*14, 416*416을 사용할 경우 13*13의 output feature map을 얻게 된다. 이 때 보통 크기가 큰 object의 중심점이 feature map에 중심에 위치하게 되기 때문에 짝수배보다는 홀수배가 다루기 쉽다. object box의 중심점을 4개의 cell에서 고려하느냐, 하나의 cell에서만 고려하느냐(single center cell)의 차이이다. 이런 방법들을 사용했을 때 mAP는 오히려 감소하는것처럼 보였지만(69.5→69.2) recall을 7%정도 향상시켜서 앞으로의 발전 가능성에 대해 얘기하고 있다.

- Dimension Clusters
Anchor Box를 도입하면서 2가지 문제점이 발생하는데 그 중 첫 번째가, Anchor box의 개수와 비율은 직접 지정해줘야 한다는 것이다. Faster R-CNN에서는 총 9가지를 지정해서 사용했었는데 여기서는 이걸 임의로 지정하지 말고 학습해서 최적의 개수를 찾아보고자 했다. VOC와 COCO training set의 bounding box를 사용해서 K-means clustering을 해보았고 최종 k=5일 때(anchor box의 개수가 5개) recall과 모델의 complexity 사이의 tradeoff 최적점이라고 발견하였다.
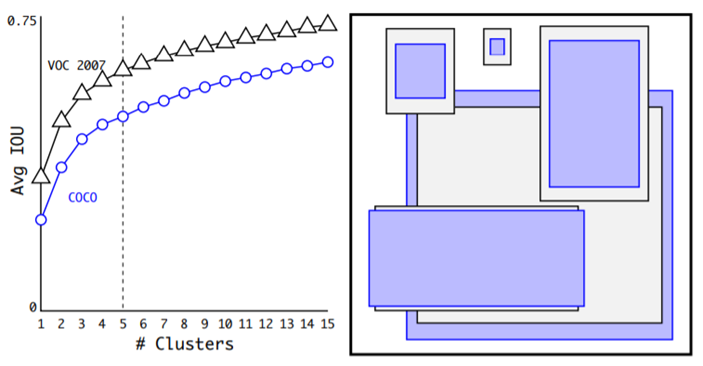
K-means Clustering은 원래 Cluster center까지의 유클리디안 거리를 계산해서 가장 가까운 cluster에 포함되도록 하는 방식인데, bounding box의 크기가 크면 당연히 거리가 더 크게 나오고 bounding box 크기가 작으면 거리가 짧게 나올 것이기 때문에 이 error를 보완해주기 위해 IOU값을 고려한 distance metric을 따로 정의해서 사용하였다.

- Direct Location Prediction
Anchor box를 도입해서 생긴 두번째 문제점으로 model instability를 제시했다. bounding box regression 계산 과정 중
center의 좌표 (x,y)를 업데이트 하는 식에서, 만약 tx=1로 예측한다면 box의 width만큼 오른쪽으로 이동시키고 같은 방식으로 tx=-1, ty=1, ty=-1일 경우에도 큰 step으로 이동시키게 된다.
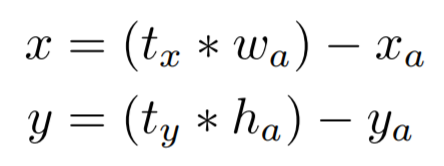
이런 방식을 사용하면 사실상 box가 image의 왼쪽 상단부터 오른쪽 하단까지 어떤 위치로든 옮겨질 수 있는데 random initialization까지 사용하면서 stabilize까지 오랜 시간이 걸리게 된다. 그래서 가까운 ground truth만 고려할 수 있도록 하기 위해 grid cell와의 상대적인 좌표를 계산하기로 했다.

특정 grid cell의 왼쪽 상단을 (Cx, Cy)라고 하고 이 cell 내에서만 update할 수 있도록 만들었고, 이 방식을 통해 5%정도 향상시켰다고 한다.
- Fine-Grained Features
416*416의 input image를 사용하면서 최종 output feature map의 사이즈는 13*13으로 바뀌었는데, 여러 모델들이 feature pyramid로 다양한 feature map을 사용하여 정확도를 올리는것처럼(FPN 논문을 보면 이해하기 sc쉽다) 하나의 map을 더 끌어다가 사용한다. 이전 Convolution layer에서 출력하는 feature map의 크기는 26*26*512인데 최종 output과 크기를 맞춰야하기 때문에 여기서는 그림과 같이 분할연결하는 방법을 사용한다. 이 방법을 통해 대략 1%정도 향상시켰다고 한다.
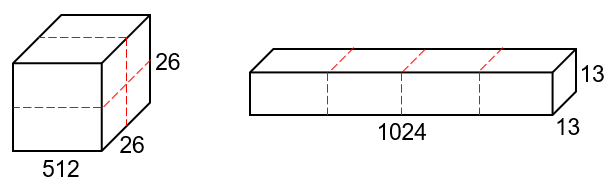
- Multi-Scale Training
전체 Convolutional Network로 이루어져있기 때문에 (fc layer 제거) 사실상 input image의 사이즈가 고정되지 않아도 된다. 그래서 Training 과정에서 여러 size의 input을 사용하여 multi-scale로 학습시키는데, 앞에서 언급했듯이 최종 output은 32배 downsampling되기 때문에 32배수의 input size를 사용한다. {320, 352, ..., 608}의 범위를 사용하였고 (라고 언급되어 있는데 성능표에서는 왜 288~544인지는 잘 모르겠다..) 사이즈별로 speed-accuracy tradeoff를 조절할 수 있다. high-resolution에서는 mAP가 높은 대신 FPS가 조금 떨어지고(그래도 여전히 빠르다) low-resolution에서는 mAP가 낮은 대신 FPS가 매우 빨라지게 된다.
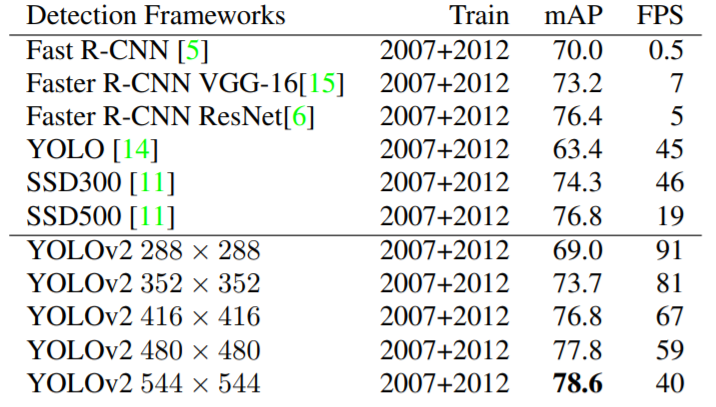
Faster
mAP를 올리면서도 빠른 모델을 만들고 싶었기 때문에 Backbone Network의 문제점을 언급하면서 바꾸고자 했다. 기존 detection model들과 YOLO에서도 사용하는 VGG-Net과 GoogLeNet은 정확도는 높지만 쓸데없이(라고 하더라..) 복잡하고 연산이 많아서 속도가 떨어질수밖에 없다. 그래서 Darknet-19라는 network를 새로 디자인해서 사용한다.
- Darknet-19
Darknet-19는 총 19개의 Convolution layer와 5개의 maxpooling layer로 이루어져있는데, 2가지 방법을 사용해서 network를 최대한 간단하고 stable하게 만들고자 했다.
- 마지막에 Global Average Pooling을 사용하여 학습 parameter수를 줄이기
- 3*3 convolution layer들 사이 중간중간에 1*1 convolution filter를 통해 channel을 줄이기
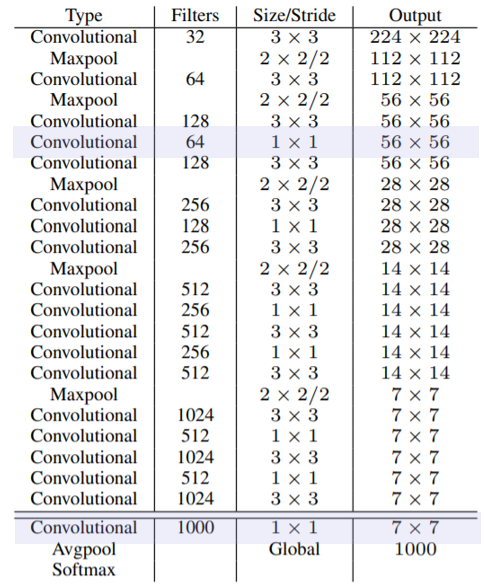
Stronger
지금까지 여러가지 방법을 통해 성능을 끌어올려서 YOLOv2를 만들었는데, 어떻게 총 9000개의 class를 구분하는 YOLO9000을 만들어낼 수 있었을까? 일반적인 dataset을 보면 Detection dataset은 수십~수백만개의 class만 다루지만 Classification과 Tagging dataset은 수만~수십만개의 class를 다루고있기 때문에 이 dataset을 적절히 섞고, jointly training을 통해 classification object categories를 대폭 늘리고자 했다.

ImageNet은 Classification, COCO는 Detection dataset인데, 위와 같은 예시를 들어보면 문제점을 볼 수가 있다. ImageNet은 더 많은 class를 다루고 있기 때문에 더 구체적인(dog, cat...) class들이 들어있고, COCO는 더 일반적인(animal...) hyponym class들이 들어있다. dataset을 바로 합치기에는 class들이 exclusive하지 않기 때문에 이미지별로 여러 예측값을 사용하는 multi-label을 사용하고자 했다. 예시로 Yorkshire terrier는 Terrior라는 class에도 속할 수 있기 때문에 Yorkshire terrier=1, Terrior=1... 과 같은 여러 lable이 나온다.
- Hierarchical Classification
다시 예시를 보면 Norfolk terrier, Yorkshire terrier, Bedlington terrior는 동시에 Dog, Mammal, Terrior등 많은 label을 가질 수 있다. 이런 구조를 계층적으로 나타내고자 했는데, ImageNet은 실제로 영어 단어의 database인 WordNet 의 구조를 따르고 있기 때문에 wordnet을 사용하여 ImageNet+COCO의 새로운 WordTree를 만든다.
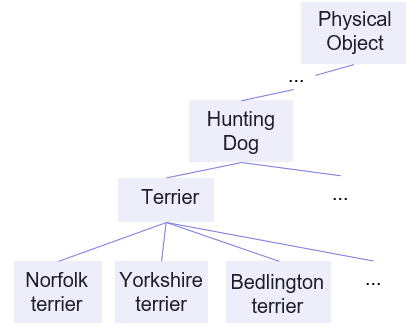
Root Node는 Physical Object이고 아래로 가장 간단한 구조부터 이어나가면서 트리를 만들어나간다. WordNet은 실제로 Tree가 아니고 Directed graph이기 때문에 특정 노드가 physical object까지 연결되는 길이 매우 많기 때문에, 가장 짧은 거리를 가지는 길을 선택하여 트리에 추가한다.
이렇게 계층적인 모델을 만들면 각 Node의 확률을 예측할 때는 조건부확률을 사용한다.

만약 특정 노드의 absolute probability를 계산한다면 physical object까지 따라 올라가면서 확률을 곱해주면 된다.

이 때 Physical object의 확률은 전체를 포함하고 있기 때문에 1이다.
이렇게 Dataset을 합쳐서 확률을 예측할 수 있게 되었고 class의 범위가 매우 넓어졌는데, Classification할 때에는 모든 class에 대해 softmax를 해야할까?? softmax를 계산할때는 같은 level 내에서 (Tree에서 같은 hyponym을 가지는 같은 level 범위) 수행하면서 따라 올라가면 된다.

Conclusion
논문에서 YOLOv2와 YOLO9000에 대해 소개했는데, 다양한 크기의 image를 다양한 class로 구분하고 detection할 수 있는 정확하고 빠른 모델이다. 계층적인 classification을 사용한 데이터셋 병합 아이디어는 Classification과 Segmentation 영역에서도 유용하게 사용될 수 있을것이고, 앞으로 더 많은 개선을 통해 Computer vision을 개발시킬거라고 기대하고 있다.
기존의 논문들과는 다른 특이한 점도 많았고(논문 자체의 구조도 독특했던 것 같다...) Dataset 병합에 대한 아이디어는 처음 접한 것 같다. mAP와 FPS까지도 동시에 대폭 끌어올린 모델이라는 점이 놀라웠고 나도 이 논문을 읽으면서 얻은 아이디어가 많아서 또 다른 연구를 시작해보기로 했다. :)
Reference
[1] qJ.Redmon et al, YOLO9000:Better, Faster, Stronger, arXiv 1612.08242
[2] qRedmon et al, You Only Look Once: Unified, Real-Time Object Detection, 2015
감자같은 학부생 혼자 읽고 기록하려고 남기는 리뷰입니다 수정할 부분은 알려주세요🥔
'Paper Review > Object Detection' 카테고리의 다른 글
| [포테이토 논문 리뷰] R-FCN:Region-based Fully Convolutional Networks (2) | 2020.11.19 |
|---|
