
Hello Potato World
[포테이토 논문 리뷰] R-FCN:Region-based Fully Convolutional Networks 본문
[포테이토 논문 리뷰] R-FCN:Region-based Fully Convolutional Networks
Heosuab 2020. 11. 19. 15:16⋆ 。 ˚ ☁︎ ˚ 。 ⋆ 。 ˚ ☽ ˚ 。 ⋆
[Object Detection paper review]
일단 오늘 읽은 paper부터 남기지만 이전에 읽은 paper들, 머신러닝 및 CNN도 기본부터 다시 봐보자는 마음으로 전부 정리할 예정
R-FCN
R-FCN(Region-based fully convolutional network)는 말 그대로 image에서의 region, 이미지 내의 object의 위치정보에 기반한 fully convolutional network다. 이 모델은 Faster R-CNN을 그대로 가져오되, RPN 이후의 단계만 수정해서 속도를 무지하게 향상시켰다. 여기서 새로 추가한(수정한) 아이디어는 크게 3가지이다.
- Fully Convolutional Network
- Position-sensitive Score Map
- Position-sensitive RoI Pooling Layer

우선 Faster R-CNN의 구조를 다시 보면, shared-convolution layers와 RPN을 통해 Region Proposal을 구하는데, 이후 classification과 Bounding-box regression을 위해 각각의 RoI에서 subnetwork를(RoI-wise라고 언급한다) 적용해야 한다. 이건 수백, 수천번이 될 수도 있는 과정이니 각 subnetwork를 전체 이미지 내에서 공유하는 fully convolutional network(FCN)로 대체한다.

여기서 image classification과 detection의 차이를 알아야하는데, 보통 convolutional layers를 거쳐 특징들을 뽑아내고 마지막에 fc계산을 통해 classification을 내리는데, 이 방식은 image에 label만 부여할 뿐, 해당 object가 이미지 내의 어디에 있는지에 대한 위치정보가 사라지게 된다.
- Translation-invariance : object의 위치가 변하더라도 출력은 동일하다. 고양이 얼굴이 어디에 있든 "고양이"만 출력
- Translation-variance : object의 위치가 변하면 출력도 위치정보에 따라 달라져야 한다.
단순히 image에 labeling을 하는 Image classification은 Translation-invariance에 해당하고 detection은 Translation-variance에 해당한다. 이 문제를 해결하기 위해 도입한 게 Position-sensitive Score Map이다.
Score map은 object에 대한 상대적인 위치를 담고있는데, 이해하기 어렵다면 heatmap의 집합이라고 생각하면 된다.

object가 존재하는 영역을 k*k의 grid로 나누어 각 총 k*k 개의 heatmap을 생성한다. 논문에서는 k=3으로 두는데 이 경우에는 Top-left부터 Bottom-right까지 총 9개로 나누어진다(생성되는 heatmap의 갯수와 분할한 object의 grid cell 개수가 같지만 헷갈리지 말자). 이 경우에는 대략적으로 Top-center에 아기의 얼굴이 들어가있겠다. 구분할 Class 갯수를 C라고 하면 background까지 포함해서 총 C+1 개에 대해 같은 방식으로 생성해준다. 다음 나눈 grid cell의 파트별로 (Top-left, Top-center...) 묶어서 차곡차곡 쌓아주면 총 k*k*(C+1) 의 dimension을 갖는 Score map이 생성된다.

이제 이 score map이 어떻게 활용되는지 봐야할텐데, model이 그림의 두 가지 경우의 RoI를 만들었다고 하면, 첫 번째 그림은 object의 위치가 feature맵에서 흰 부분과 많이 겹치지만 두번째는 아닌걸 볼 수 있다. 예를 들면 아기의 손 부분은 실제 object의 손이 위치하는 부분에서 아예 벗어났기 때문에 거의 까맣게 나오는 걸 볼 수 있다. 이렇게 각 부분별로 계산해서 구하기 위해 도입한 게 Position-sensitive RoI Pooling layer이다.

Convolutional layer로 뽑아낸 Score map과 Pooling을 사용해서 RPN에서 뽑아낸 각각의 RoI에 대해 한번에 연산할 수 있는 과정이다.
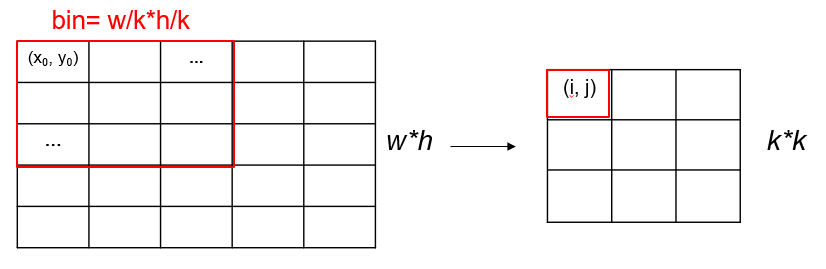
앞에서 object를 k*k 로 나눠줬었으니 pooling 결과도 k*k 로 나와야 한다. 각 RoI의 크기는 전부 다를테니 w*h 라고 하자. map의 하나의 cell에 매핑되는 RoI의 pixel영역들의 집합을 bin이라고 하면, bin의 크기는 w/k*h/k 가 된다. bin의 pixel들을 (x, y)라고 하면 각 (i, j)에 매핑될 픽셀들의 범위를 구할 수 있다.
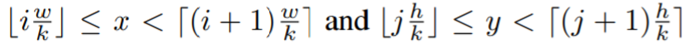
이제 각 cell에 들어갈 값(r)을 구하는데, 논문에서는 Average Pooling을 사용하고 있지만 다른 방법을 사용해도 괜찮다고 한다. 여기서 n이 하나의 bin에 포함되는 pixel의 개수이고(Average), ∂는 network의 학습 가능한 모든 파라미터를 의미한다. (특수문자 못 찾게써여..)
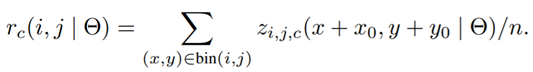
- rc(i,j)는 c번째 category(class)에서 (i, j) pooling 결과값
- (x0, y0)는 하나의 RoI의 top-left corner
- zi,j,c는 k*k*(C+1) 개의 score maps 중 하나
여기서 중요한 게 일반 Pooling과는 다르게 Selective Pooling을 한다는 거다. 모든 channel에 대해 수행하는 게 아니고 같은 위치정보를 갖는 channel에만 계산한다. [Figure5]를 다시 보면 이해가 쉬울 것 같다. 주황색 영역은 주황색 영역에서, 노랑색 영역은 노랑색 영역에서.... 앞에서 본 것처럼 각각의 파트 (Top left, Top center...) 에 대해서만 계산하는거다. 이렇게 Pooling을 진행하고 나면 C+1 의 channel을 가지게 된다. 여기서 각k*k 개의 score를 Average 내주면(Voting) C+1 차원의 vector가 한 개 생성된다.

이제 이 vector는 각 클래스의 score 점수를 가지고 있으니, softmax를 통해 최종 prediction을 만들면 되겠다.

논문에서 자세하게 언급하지는 않았는데, Classification과 같은 방식으로 4k*k-d의 convolution layer를 생성하고 최종적으로 4-d의 vector를 생성하면 bounding box의 coordinate정보(x,y,w,h)를 담게 된다. 이렇게 하면 Bounding-box regression까지 계산할 수 있다.
Loss Function

Loss Function은 기존의 다른 모델들과 다를 게 없다. Classification과 Regression의 loss의 합으로 이루어진다. 여기서 c*는 RoI의 Ground Truth 값, t*는 box의 Ground Truth값이고, c*=0은 background를 의미하기 때문에 regression은 background를 제외하고 계산해준다.
이 function은 계속계속 나오니까 나중에 따로 정리하겠다!
Conclusion
이렇게 하면 처음 목표했던 대로 하나의 shared fully-convolutional network로 연산을 수행할 수 있고, RoI 각각에 대해 따로 계산해주는 게 아니기 때문에 RoI의 개수는 속도에 영향을 거의 미치지 못한다. 정확도가 뛰어나게 좋아지지는 못했지만 속도면에서는 획기적으로 절반 이상 줄인 걸 확인할 수 있다. 다른 detail 방법들로 정확도를 조금씩 높이기도 했는데, 이정도 큰 틀만 이해해도 좋을 것 같다.
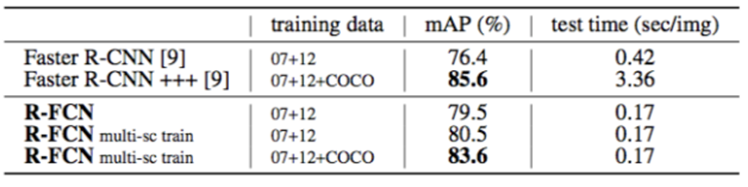
논문에서는 다른 1-Stage model(Yolo, SSD etc.)보다 2-Stage model이 mAP면에서 더 좋을 수 있어서 Faster R-CNN을 사용했다고 했는데, 그 부분은 조금 갸우뚱싶다는 생각이 들었다. 다른 model에도 적용 할 수 있는 방법이 있을까?
Reference
[1] Jifeng et al, R-FCN: Object Detection via Region-based Fully Convolutional Networks
[2] qRen et al, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2015
[3] Shelhamer et al, Fully Convolutional Networks for Semantic Segmentation
감자같은 학부생 혼자 읽고 기록하려고 남기는 리뷰입니다 수정할 부분은 알려주세요🥔
'Paper Review > Object Detection' 카테고리의 다른 글
| [포테이토 논문 리뷰] YOLO9000: Better, Faster, Stronger(&Yolov2) (0) | 2020.12.04 |
|---|
