
Hello Potato World
[포테이토 논문 리뷰] Spatiotemporal Contrastive Video Representation Learning 본문
[포테이토 논문 리뷰] Spatiotemporal Contrastive Video Representation Learning
Heosuab 2022. 10. 6. 18:01⋆ 。 ˚ ☁︎ ˚ 。 ⋆ 。 ˚ ☽ ˚ 。 ⋆
[Video paper review]
Pre-text task
양질의 데이터셋에 전부 라벨링을 하는 것은 비용이 크기 때문에, label이 없이 학습하는 unsupervised learning이 많이 연구되고 있다. 그 중에서도, label이 없는 데이터셋 내에서 학습하고자 하는 문제(Pre-text task)와 label을 대체할 수 있는 target을 직접 정의하여 supervision으로 학습하는 방법을 self-supervised learning이라고 한다.
Contrastive learning은 self-supervised learning의 대표적인 방법 중 하나로, input sample들 사이에서 positive pair를 묶은 후에 embedding space 내에서 positive sample끼리는 까가워지고 negative sample끼리는 멀어질 수 있도록 학습하는 방식이다.
Figure 01은 각각의 이미지에 augmentation을 적용하여 2개씩 positive pair를 생성하고, 이 정보를 target으로 학습하는 contrastive learning의 예시이다.

Image-based에서 주로 사용하던 방식인데, 해당 논문에서는 temporal 정보를 가지는 video 데이터에 적용해보고자 했다.
Self-supervised Contrastive Video Representation Learning (CVRL)
저자들은 Label이 없는 video 데이터로부터 spatiotemporal visual representations를 생성할 수 있는 Self-supervised contrastive video representation learning (CVRL)을 제안한다. Figure 01와 같이 augmentation을 통해 pair를 생성하는데, single image와 달리 video 데이터는 spatial, temporal 정보가 모두 중요하기 때문에 두 가지를 모두 사용하는 spatiotemporal augmentation을 보인다.
CVRL의 전체적인 과정은 총 4 step으로 나눌 수 있다.
- Raw video data로부터 clip samples 생성 (Temporal augmentation)
- Clip samples에 image-based augmentation 적용 (Spatial augmentation)
- Video encoder를 통해 각 clip의 embedding 생성
- 추출된 embedding으로 contrastive learning
- Step 1. Raw video data로부터 clip samples 생성 (Temporal augmentation)
Raw video 데이터셋이 주어지면 contrastive learning을 위해 필요한 positive pair를 생성해야하기 때문에, 각 video마다 2개의 clip(일부를 추출한 짧은 영상)을 추출한다.
이 때 video의 다양한 시간 정보를 학습하고 활용하기 위해서는 어떤 부분의 clip을 선택하는지가 중요한데, 기존에는 frame이나 clip 단위로 video를 섞어버리거나 재생속도를 변화시키는 등의 temporal augmentation을 사용해왔다. 하지만 이 방법은 video 내의 본질적인 temporal feature를 뭉개버릴 수가 있다고 한다.
또한 video 내의 장면들은 시간에 따라 계속해서 변화하기 때문에, 선택된 두 개의 clip이 temporal하게 너무 멀면 visual content가 너무 다른 pair가 positive로 생성될 수 있기 때문에 학습이 어려울 수 있고, 그렇다고 temporal하게 먼 clip들을 완전히 버려버리는 건 temporal augmentation 효과가 감소된다고 한다.

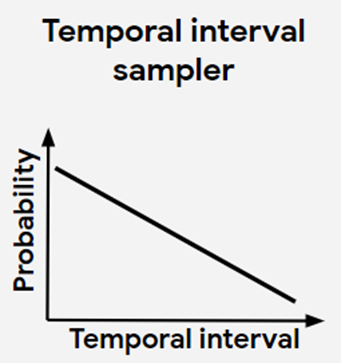
위의 두 가지 문제를 해결할 수 있는 sampling strategy를 제안한다.
Temporal하게 가까울수록 probability가 높게, 멀수록 probability가 낮게 만들기 위해서 단조 감소 확률분포를 정의하고, 두 개의 clip의 start point 사이의 거리인 time interval t 를 이 분포 내에서 sampling한다.
- 전체 Video time length을 T라고 하면, 구간 [0, T]를 가지는 distribution에서 time interval t 를 선택한다.
- [0, T-t] 구간에서 첫 번째 clip을 sampling하고, (두 번째 clip이 T를 넘지 않게 하기 위해)
- 첫 번째 clip으로부터 +t 시점에서 두 번째 clip을 추출한다.
이 sampling 방법을 통해 다양한 시점에서 생성된 clip pair들을 얻을 수 있기 때문에, 이전의 단점들을 개선한 temporal augmentation을 적용할 수 있다.
- Step 2. Clip samples에 image-based augmentation 적용 (Spatial augmentation)
Flip, rotate, color jittering 등 image augmentation에 자주 쓰이는 method를 각각의 clip의 frames에 적용한다. 이 때 개별 frame마다 서로 다른 augmentation을 적용하기 때문에, 자칫 video 내의 연속되는 motion 정보를 망가뜨릴 수가 있다. 따라서 이 논문에서는, colorize, temporally하게 consistent한 augmentation만 적용한다.
이 방법을 통해 Spatial augmentation도 따로 적용하게 되어, Step 1과 함께 spatiotemporal augmentation이라고 할 수 있다.
- Step 3. Video encoder를 통해 각 clip의 embedding 생성
3D-ResNets를 backbone으로 사용하여 video embedding을 생성하는 encoder를 구성했다. 아래의 두 가지 작은 수정을 제외하고는 SlowFast network의 "slow" pathway를 따랐다고 한다.
- Data layer의 temporal stride를 2로 사용
- 첫 번째 convolution layer의 temporal kernel size를 5로, stride를 2로 사용

- Step 4. 추출된 embedding으로 contrastive learning
각 video마다 2개의 positive pair embedding을 생성했다면, embedding space 내에서 positive clip끼리는 가까워지게, negative clip끼리는 멀어지게 학습할 수 있도록 loss를 정의해야 한다. 이 논문에서는 InfoNCE contrastive loss를 적용한다.

Figure 05는 InfoNCE contrastive loss의 수식이다.
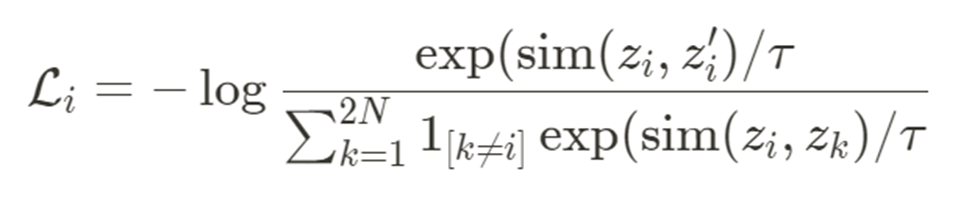
- 총 N개의 raw video가 주어졌을 때, 앞서 step의 augmentation을 통과하면 총 2N개의 clips이 생성된다.
- i번째 input video에서 추출된 pair의 각 encoded representation을
- 거리를 계산하는 sim은 cosine similarity를 사용하며 (
- 분모의
Results

Sampling strategy에서 서로 다른 distribution을 사용했을 때의 성능 비교 결과이다. (a)와 같이 일정하게 감소하는 확률분포가 가장 높은 accuracy를 보였다.

해당 논문에서는 video representation learning에서의 spatiotemporal augmentation 기법의 중요성에 대해 강조하고 있다. 실험적으로도 증명했는데, Figure 08에서와 같이 temporal, spatial augmentation을 모두 적용했을 때 accuracy가 가장 높게 나온 것을 볼 수 있다. Temporal consistency는 Step 2에서 적용한 방법을 나타낸다.

Kinetics-600 데이터셋에서 다양한 spatiotemporal representation method를 적용한 accuracy 비교이다. 기존에는 supervised와 unsupervised learning의 성능 차이가 현저하게 났었는데, CVRL이 unsupervised method들의 성능을 크게 뛰어 넘어서 supervised와 unsupervised사이의 gap을 많이 줄인 것을 볼 수 있다.
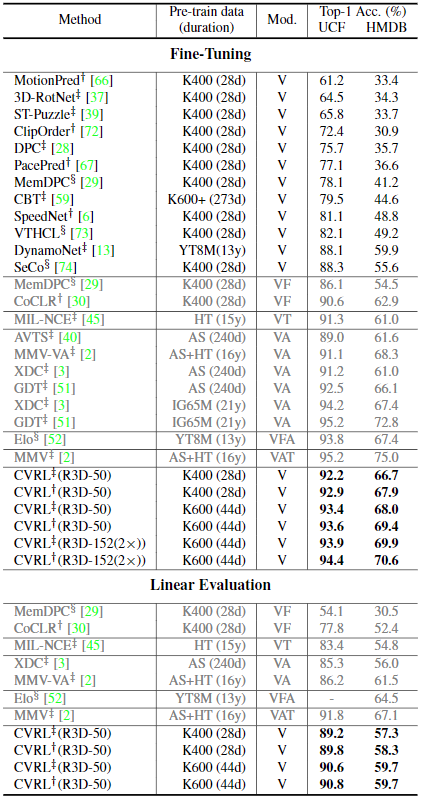
Label이 없이 학습하는 method들은 그 자체로 evaluation을 하기가 쉽지 않아서 subtask로 downstream하여 해당 성능을 평가하는 방식을 많이 사용하고 있다. Figure 10는 action classification subtask로 downstream해서 성능을 평가한 표이다.

서로 다른 양의 video를 가지는 Kinetics-400과 Kinetics-600 데이터셋에 CVRL을 적용한 결과이다. CVRL은 데이터의 양이 많을수록 좋은 성능을 보인다고 한다.
References
'Paper Review🥔 > Video' 카테고리의 다른 글
| [포테이토 논문 리뷰] MOTR: End-to-End Multiple-Object Tracking with TRansformer (7) | 2021.06.24 |
|---|
