
Hello Potato World
[포테이토 논문 리뷰] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization 본문
[포테이토 논문 리뷰] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Heosuab 2021. 8. 8. 20:47
⋆ 。 ˚ ☁︎ ˚ 。 ⋆ 。 ˚ ☽ ˚ 。 ⋆
[XAI paper review]
Generalization to CAM
모델을 해석할 때에는 Simplicity와 Interpretability사이의 tradeoff 관계가 있다. 즉, 모델이 간단할수록 해석은 용이해지고 모델이 복잡할수록 해석은 어려워지기 때문에 모델의 accuracy를 잃지 않으면서 해석하기 위해서는 이 둘 사이의 적정점을 찾는것이 중요하다.
지난번 리뷰했던 CAM에서는, CNN모델의 가장 마지막 layer인 FC layer를 Global average pooling으로 대체하여 overfitting을 줄이고 학습되지 않은 task(weakly-supervised object localization)을 수행하여 시각화할 수 있다는 장점이 있었다. 하지만 GAP로 대체하는 과정이 결국 모델의 해석을 위해 complexity를 줄인 것이며, CAM은 마지막 FC layer를 포함하는 모델에만 한정적으로 적용할 수 있다는 단점이 있다.
이 논문에서 제시하는 Grad-CAM은, 모델의 구조나 complexity에 아무 변형을 주지 않고 모든 모델에 적용할 수 있는 알고리즘이다. 따라서 CAM의 일반화된 방법이라고 볼 수 있고, 다음과 같은 더 넓은 범주의 CNN모델에 전부 적용할 수 있기 때문에 Image Classification, Localization, Captioning, VQA(Visual Question Answering)등의 더 넓은 Task에 응용된다.
- FC layer가 없는 CNNs
- Image Captioning처럼 구조화된 output을 만드는 CNNs
- VQA처럼 multi-modal의 input을 사용하는 CNNs
- 강화학습
Grad-CAM (Gradient-weighted Class Activation Mapping)

CAM에서 사용했던 Global average pooling에서는, 마지막 Convolution layer의 Feature map 각각에 대해 전역적인 평균값을 구한 후 각 unit $k$에 대한 중요도를 의미하는 weight들을 사용하여 weighted sum을 하였다. 하지만 위에서 언급했던 문제점처럼, 이 weight 값들이 주어져있지 않으면 CAM을 사용할 수 없기 때문에 Global average pooling을 사용하는 CNN 모델에만 CAM을 적용할 수 있다는 문제점이 생긴다. 따라서 이 논문에서는 이 weight들을 각각의 class c에 대한 gradient backpropagation으로 계산하여 대체하고자 한다($\alpha_k^c=w_k^c$). 이 $\alpha$값을 구하는 방법은 아래에서 소개한다.

위의 그림은 Global Average Pooling이 아닌 FC layer이 사용된 모델의 예시이다. Softmax layer를 통과하기 이전의 output을 $y^c$(각 Class c에 대한 결과값)이라고 하면, 마지막 convolution layer의 feature map인 $A^k$의 영향을 계산하기 위해 각 class의 gradient를 계산한다.
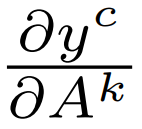
Gradient를 $A^k$내의 모든 (i,j)의 뉴런에 대해 계산하고 Global average pooling을 하여, 각 $A^k$에 대한 하나의 importance weight $\alpha_k^c$를 구할 수 있다(Z는 average를 위한 i*j). 이 때 class c에 대한 output인 $y^c$와 feature map $A^k$를 사용한 backpropagation을 수행했기 때문에, 각각의 $\alpha_k^c$는 target class c에 대한 feature map k의 영향력(중요도) 정보를 의미한다.
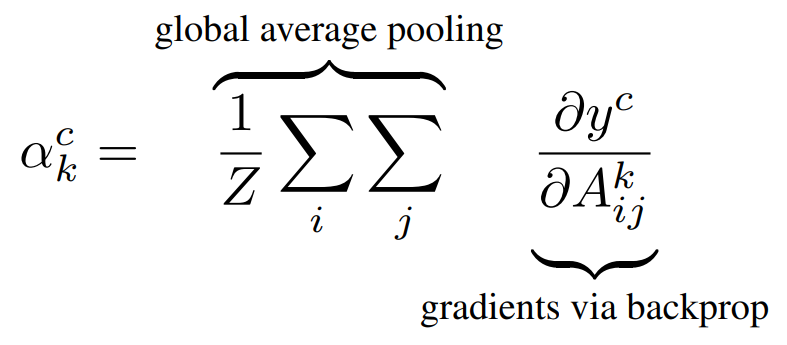

앞서 CAM에서 확인할 수 있었던것처럼, 구해진 가중치(중요도) $\alpha_k^c$와 feature map $A^k$의 linear combination연산을 하면 Grad-CAM을 구할 수 있다. 아래 수식처럼 ReLU연산을 한번 더 수행하는 이유는, 영향력을 분석하고자 하는 각 class c에 대해 positive한 영향을 미치는 feature들만 나타내기 위해서다. (positive한 영향이란, 해당 feature들의 intensity가 증가하면 $y^c$값이 증가하는 것을 말한다.) ReLU의 특성상, negative 값을 가지는 feature들은 0으로 근사하게 된다.
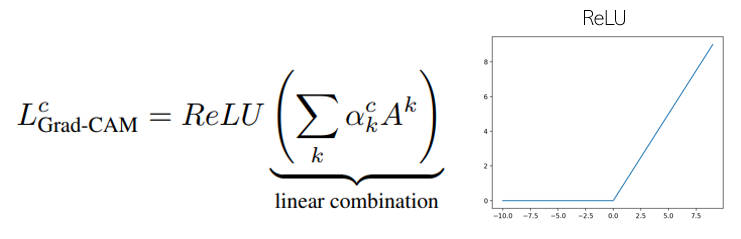
Guided Grad-CAM (Guided Backpropagation + Grad-CAM)

위의 그림은 하나의 이미지에 대해 "Tiger cat"(상단 줄)과 "Dog"(하단 줄) 두 가지 class의 분석을 시각화한 것이다.
Guided Backpropagation이나 Deconvolution와 같은 Pixel-space Gradient Visualizations의 경우 이미지의 세부적인 디테일을 하이라이트하기하기 때문에 각 class에 대한 차별적인 결과를 만들어주지는 못한다. 예를 들어 (b)는 "Cat"에 대한 시각화 이미지이고, (h)는 "Dog"에 대한 시각화 이미지인데, 두 이미지 모두 pixel 단위까지 세부적으로 분석했지만, 고양이와 강아지 영역이 전부 하이라이트되어 두 이미지에 큰 차이가 없다는 것을 볼 수 있다.
반면 CAM이나 Grad-CAM과 같은 localization approaches의 경우 각 class에 대한 차별적인 결과를 만들어주지만 세부적인 디테일은 잡아내지 못한다. 그림에서 (c)와 (i)를 보면, 각 class에 영향을 미치는 고양이와 강아지의 영역을 히트맵처럼 두루뭉술하게 하이라이트한 것을 볼 수 있다.
Guided Grad-CAM은 이 두 방법의 장점들을 융합하여 class-discriminative하면서도 high-resolution한 시각화를 제공하고자 만들어졌다. 그림에서 (d)와 (j)를 보면, pixel 단위까지 세부적으로 분석하면서도 각각의 class에 맞는 영역들만 하이라이트한 것을 볼 수 있다. 이렇게 class-discriminitive한 알고리즘은, 모델의 prediction이 틀렸을 경우에도 왜 틀린 예측을 만들었는지에 대한 논리적 근거를 찾을 수 있게 된다.
Application Tasks

Grad-CAM의 전체적인 구조를 나타낸 그림이다. 앞서 backpropagation에 사용했던 $y^c$는, Image Classification의 class score값일수도 있지만, 다른 여러가지 형태를 가질 수 있다.
구조화된 output caption의 activation값이라면 Image Captioning에 적용될 수도 있고, 질문에 대한 answer의 activation값이라면 VQA에 적용될 수도 있다.
또, CAM은 마지막 Convolution layer의 feature map에만 한정해서 시각화할 수 있었지만, Grad-CAM은 backpropagation을 통해 가중치를 계산하기 때문에 중간의 다른 convolution layer에 대해서 시각화할 수도 있다.
Results

위 그림은 "What Color is the firehydrant?"라는 질문에 대한 VAQ에 알고리즘들을 적용한 것이다. "red", "yellow", "yellow and red"라는 세 개의 class에 대해 시각화했을 때, Guided Backpropagation은 모두 비슷한 이미지를 보였고, Grad-CAM과 Guided Grad-CAM은 각 class에 영향을 크게 미치는 영역들을 올바르게 하이라이트하였다.

더 복잡한 모델에 대해서도 해석 가능한 설명을 제공할 수 있다고 한다.

위 그림은 Image Captioning model에 적용한 결과이다. caption output을 예측하는데 크게 영향을 미친 영역들을 하이라이트한 것을 볼 수 있다.

VGG-16이 분류를 실패한 이미지들에 대해 Guided Grad-CAM을 시각화한 그림이다. 사람이 눈으로만 봐서는 모델이 왜 잘못된 예측을 만들어냈는지 확인하기 어렵지만, 이 알고리즘을 사용하면 이유를 확인할 수 있다.
예시로, (b)의 이미지의 경우 실제 라벨은 "volcano"이지만, 이미지의 volcano보다는 주변의 창문틀이 더 강조되어서 모델이 "car mirror"로 잘못된 prediction을 만들어냈다고 판단할 수 있다.
References

