Hello Potato World
[포테이토 논문 리뷰] MOTR: End-to-End Multiple-Object Tracking with TRansformer 본문
[포테이토 논문 리뷰] MOTR: End-to-End Multiple-Object Tracking with TRansformer
Heosuab 2021. 6. 24. 15:50
⋆ 。 ˚ ☁︎ ˚ 。 ⋆ 。 ˚ ☽ ˚ 。 ⋆
[Video Tracking paper review]
최근 MOT에 관심이 생겨서 관련 내용들이나 issue들에 관해 공부해보고자 했는데, MOT연구 동향의 큰 흐름과 중요한 issue들을 잘 보여주고 있어서 매우 유익했던 논문이다. 특히 최근에 딥러닝 분야를 흔들고 있는 Transformer에 흥미가 많았는데 Video Tracking에서도 활용되어 좋은 성능을 보이고 있다는 것을 볼 수 있었어서 더욱 인상깊었던 것 같다.
MOTR
MOTR은 Transformer기반의 구조로 구성되어 있고, 아래 3가지 concept들을 통해 기존 MOT의 전통적인 framework의 문제점들을 해결하였다.
- 전체 구조가 end-to-end 로 연결된 framework
- Track query 의 개념 도입과 contiguous query passing 매커니즘의 활용
- Multi-frame training와 결합된 Temporal aggregation network(TAN) 활용
Traditional MOT
MOT(Multiple Object Tracking)는 영상 내에서 여러개의 object의 trajectory를 트랙킹하는것으로, 여러 object를 동시에 처리하면서도 동시에 긴 시간의(long-term) 정보를 트랙킹할 수 있어야한다. 트랙킹을 위해 비디오 내의 모든 frame에서 object의 위치를 추출해야 하는데 영상 내의 다른 object에 의해 가려지는 등의 제한적 상황때문에 long-term tracking이 어려울 수 있고, 이 challenge를 해결하기 위해 기존 모델들은 Tracking-by-detection framework를 사용하고 있다.
- Tracking-by-detection

Tracking-by-detection은 두 가지의 구성으로 나뉘어져 최종 trajectory를 예측한다.
- Object Localization(=Object Detection) : Object Detector가 매 frame에서 객체의 위치 추출
- Temporal Association(=Data Association) : Tracker가 연결된 앞뒤 frame의 위치정보를 연결해서 trajectory 예측
여기서 Tracker가 각 frame에서 추출된 위치정보를 연결하는데 사용되는 방식은 대표적으로 2가지가 있다.

1. IoU based object trackers (spatial)
공간적 유사도를 판정하는 첫 번째 IoU based 방식은, 각 frame에서 추출된 bounding box의 IoU값을 계산하여 연결한다. IoU matrix를 통해 두 개의 연속된 frame내의 각 object간의 위치 영역의 교집합을 계산하고 겹치는 영역이 일정 threshold 이상이면 같은 object라고 판단하는 방법이기 때문에, bounding box의 위치 계산을 돕는 Box regression(B)과 Classification(C) 두 개의 branch만을 사용한다.
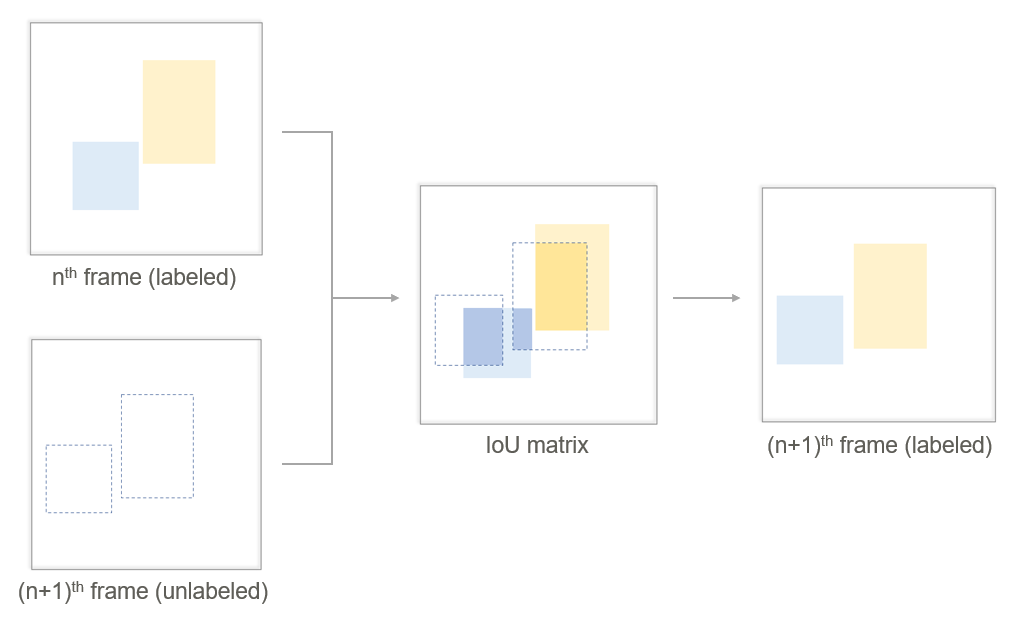
2. Re-ID based object trackers (appearance)
형태적 유사도를 판정하는 두 번째 Re-ID based 방식은 Re-ID(R)에 해당하는 하나의 branch를 추가한다. 이 branch를 통해 Re-ID feature embedding을 예측하고, 연속된 두 frame에서 각 feature의 형태적인 유사도를 계산하여 높은 유사도를 가지는 쌍을 같은 object로 판단한다.
이렇게 두 가지 단계로 나뉘어져 있는 Tracking-by-detection framework는 구조가 너무 단순하기 때문에 추적이 끊기는 frame이 생기는 영상을 다루기 힘들고, 따라서 기존 모델들은 데이터로부터 temporal variation을 학습할 수 없다. MOTR이 이 문제를 어떻게 해결했는지 아래 방법들을 살펴보자.
Track Query
Transformer를 사용한 Object Detection model인 DETR(Detection TRansformer)라는 모델에서는, transformer구조를 사용하기 위해서 "Object Queries"라는 개념을 도입했었다. Object query는 고정된 개수의 학습된 positional embeddings로, 각 object class에 대해 이분적인 값을 가진다. DETR이 detection에서 매우 좋은 성과를 거두었기 때문에, 이 object queries를 본따 "Track Query"라는 개념을 도입했다.
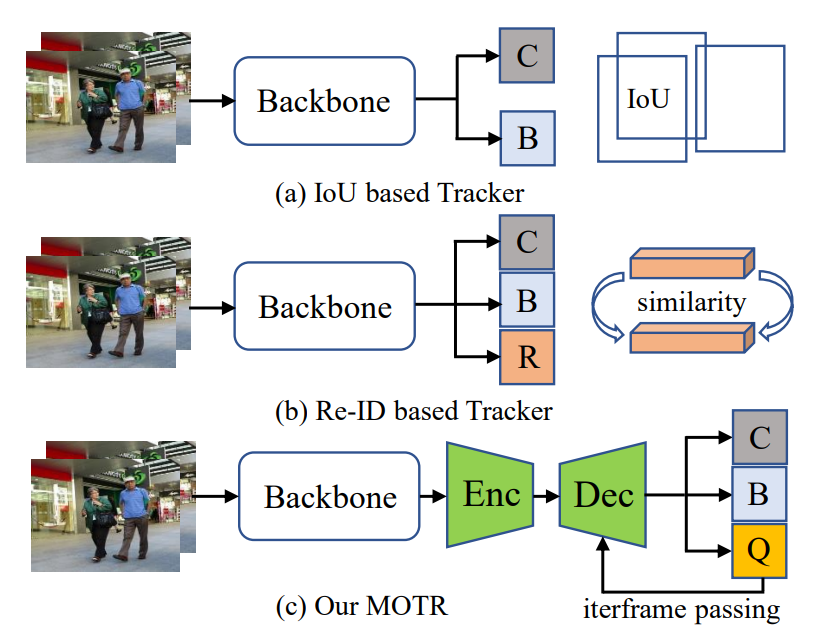
앞서 보았던 다른 Traditional MOT 모델들과 비교해보면, MOTR은 기본적으로 Encoder와 Decoder를 가지는 Transformer구조를 가지며, Track Query에 해당하는 새로운 branch를 사용한다. MOTR는 매 frame마다 Track query set을 예측하는데, 이 Track Query set은 각 object가 영상 내에 등장해서 사라질때까지의 전체 track을 예측한다.
Track query set은 decoder에 input으로 들어가면 현재 frame에 대한 tracking prediction을 만들고, output으로 업데이트된 track query set은 다음 frame의 decoder에 input으로 또 다시 사용된다. 이런 recurrent한 query passing은 전체 비디오 내에서 frame별로 반복되는데, 이것을 continuous query passing이라고 한다.
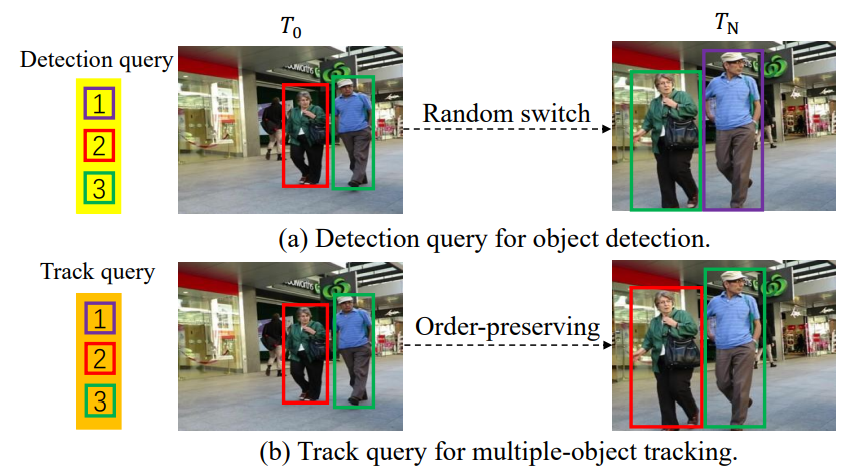
DETR의 object query는 특정 object에 대해서만 예측하도록 설계되어있지 않아서 하나의 object query가 여러 object에 대한 track을 예측하게 될 수도 있다. 위 그림의 (a)를 보면 3번 query(초록색)가 다른 frame 내에서 서로 다른 object의 위치를 예측하고 있는 것을 볼 수 있다.
반면 track query는 어떤 한 frame 내에서 한 object에 매칭되고 나면, 이후 해당 object가 사라지기 전까지는 그 object에 대한 예측만 수행한다. 그림의 (b)를 통해 2,3번 query가 다른 frame 내에서도 각자 같은 object의 위치를 예측하고 있는 것을 볼 수 있다. 따라서 예측된 track과 object 사이의 연결(detection-by-tracking에서의 temporal association과정)이나 NMS와 같은 수작업 과정을 제거하고 전체 구조를 end-to-end로 만들 수 있게 된다.
Continuous Query Passing
Continuous Query Passing 과정을 구조와 수식적으로 좀 더 자세히 보면, 영상 중간의 frame에서 등장하거나 사라지는 object들의 추적을 어떻게 제어하는지와 query가 어떻게 전달되는지 확인할 수 있다. 아래 그림이 전체적인 passing 과정을 보여주고 있다.

우선 전체 비디오(Video sequences)가 input으로 입력되어 CNN을 통과하고 나면, Deformable DETR의 encoder를 거쳐 feature의 리스트 $f = {f_0, f_1, ... , f_N}$이 추출된다. (Deformable DETR은 DETR의 Transformer에서 self-attention를 multi-scale deformable attention으로 대체하여 단점을 보완한 모델로, MOTR의 encoder와 decoder는 Deformable DETF을 참조한다)
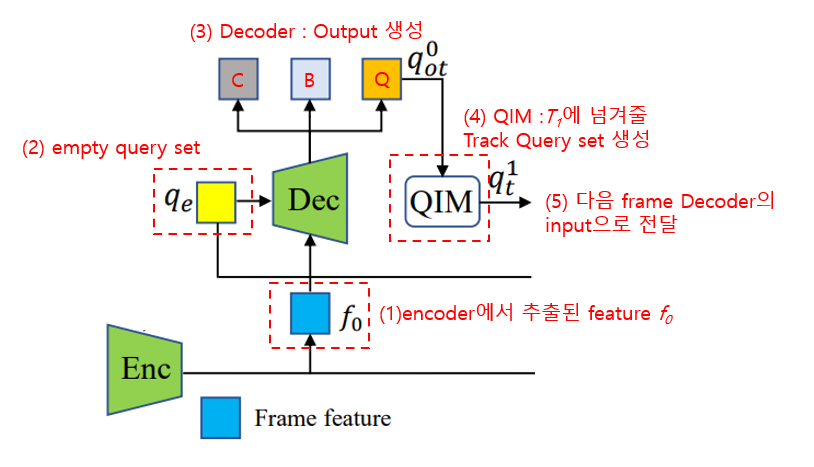
비디오의 각 frame을 $T_0, T_1, ... , T_N$이라고 할 때, 최초 frame인 $T_0$의 Decoder input으로는 basic feature인 $f_0$과 비어있는 query set인 $q_e$이 들어와서 모든 객체의 initial 위치를 추출하고 original track query set인 $q^1_{ot}$을 생성한다. 이 $q^1_{ot}$은 Query interaction module(QIM)을 통과하여 다음 frame $T_1$에 넘겨줄 track query set $q^1_t$을 생성하고, 최종으로 $f_1$과 함쳐진 input이 다음 frame decoder의 input으로 들어가게 된다. 이 과정이 전체 video sequence 내에서 반복된다.
Query Interaction Module(QIM)
위에서 $T_0$의 track query 처리 과정에 나왔던 QIM이 새로 등장하고 사라지는 object들을 처리할 수 있도록 해주는 핵심 매커니즘으로, Temporal Aggregation Network (TAN)이라는 구조를 포함한다. TAN은 과거에 처리한 frame들에서 추적한 object들에 대한 query를 모으고 한번에 처리해주는 Query memory bank와 같은 역할을 하고, 현재 frame의 track query는 multi-head attention을 통해 memory bank내의 각각의 query와 상호작용하게 된다. 여러 frame의 정보를 활용하여 예측을 만드는 Multi-frame training과 TAN이 결합된 Multi-frame temporal aggregation도 전통적인 MOT 구조의 문제점을 해결하는데 큰 역할을 했다고 한다. 아래 그림은 QIM을 좀 더 자세히 보여주는 $T_i$ frame의 track query 처리 과정이다.
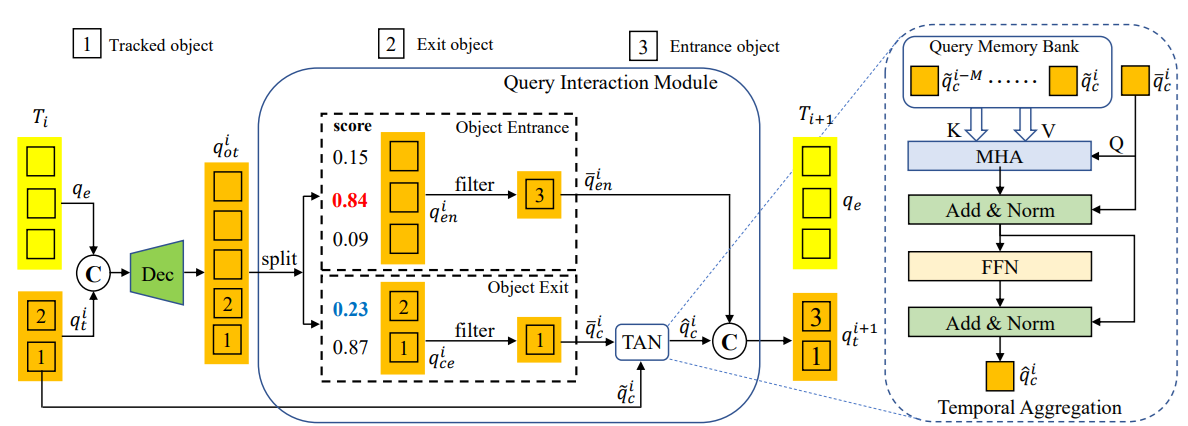
MOTR의 Track query는 한번 특정 object에 매칭되고 나면 해당 object만 추적하기 때문에, 매 frame별로 새로 등장하는 object(entrance)에 매칭할 빈 query가 있어야 하고, 매 frame에서 사라지는 object(exit)가 있으면 추적중이던 query를 삭제해야 한다. Training 과정에서, 객체의 entrance와 exit의 판별은 track score를 사용하여 예측한다.(ground-truths와의 매칭으로 계산)
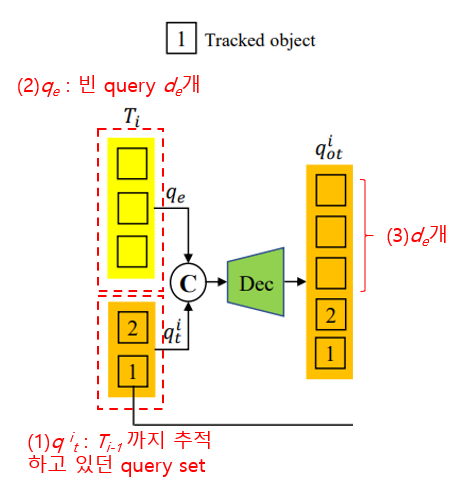
$T_i$번째 frame의 Decoder input은, $T_{i-1}$frame에서 전달받은 query set $q^i_t$와 빈 객체 $q_e$를 병합하여 입력받는다. Decoder가 original track query인 $q^i_{ot}$를 track score와 함께 생성하고 나면, index $d_e$를 기준으로 두 개의 query set으로 분할한다.
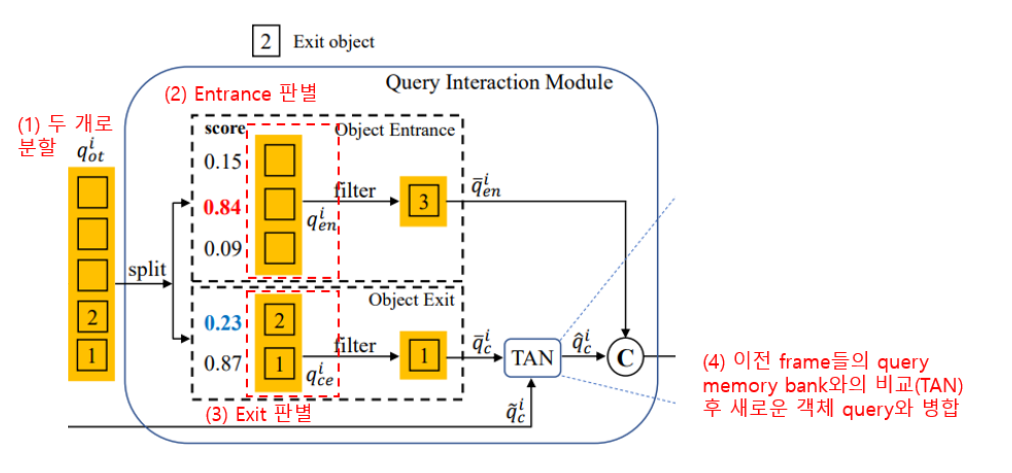
0번째부터 $d_e-1$까지(빈 query)와 $d_e$부터 마지막 index(추적중이던 query)로 두 set으로 분할하게 되면, 첫번째 set인 $q^i_{en}$는 entrance object의 판별을 담당하고 $q^i_{ce}$는 tracked와 exit object의 판별을 담당한다.
- Entrance : 앞에서 언급한 것처럼 Ground Truth와의 비교를 통해 score를 함께 생성하는데, 미리 지정된 임계치값 $\tau_{en}$보다 score가 큰 경우에 새로 생성된 object가 맞다고 판단하여 해당 query만 남겨두고, 나머지 score가 작은 query들은 삭제한다. 위의 그림 예시의 경우, $\tau_{en}$=0.8로 설정되어있기 때문에 0.84의 score를 가지는 query(object="3")만 남고 모두 삭제된다.

- Tracked & Eixt : Exit 판별에서는 현재의 frame만 보는 것이 아니라, 이전의 연속된 총 $M$개의 frame정보를 확인하여 $M$개의 query score의 최댓값이 지정된 임계치값 $\tau_{ce}$보다 작을경우 사라진 object라고 판단하여 삭제한다. 위의 그림 예시의 경우, $\tau_{ce}$=0.6, $M$=5로 설정되어있어서, 현재 $T_{i-5}~T_i$ frame에서의 query score 최대값이 0.23인 query(object="2")는 삭제된다.


tracked query는 TAN을 통해 이전까지의 query memory bank 상호작용하여 새로 build-up 된다. memory bank $q_{bank} = \lbrace\tilde{q}^{i-M}_c\, ... , \tilde{q}^i_c\rbrace$는 과거 $M$개의 frame을 병합해서 만들어진다.
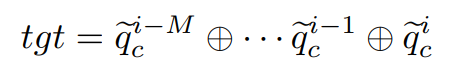
$tgt$가 TAN의 multi-head attention(MHA) 모듈에 input으로 들어오면(value:V, key:K 둘 다 input), attention weight를 생성한다. 함께 input으로 들어온 $\bar{q}^i_c$와의 내적을 통해 계산된다.

이후 $q^i_{sa}$가 feed forward neural network(FFN)을 통과하고 다시 Normalized까지 거치고 나면 최종 output인 $\hat{q}^i_c$가 생성된다. 최종 output은 현재 frame의 entrance query와 결합되어 다음 frame으로 전달된다.
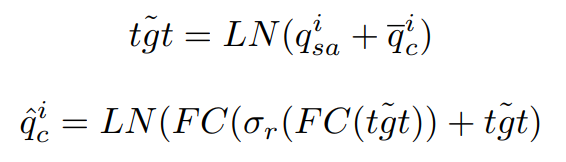
Conclusion
7개의 training sequences와 7개의 test sequences를 포함하는 MOT16, MOT17 dataset을 사용했다.(same video)

여러가지 metrics를 통해 다른 Tracker model들과 비교해봤을 때, MOTR이 훨씬 좋은 성능을 보여주고 있는걸 확인할 수 있었다. 특히 MOT17에서 TrackFormer와 TransTrack과 비교해보았을때, 다른 두 모델도 Transformer 구조를 사용했지만 MOTR이 훨씬 좋은 성능임을 볼 수 있다. 기본적인 구조는 공통점이 많지만, MOTR이 (1)첫 fully end-to-end framework를 사용하며 NMS의 필요성을 제거했고, (2) multi-frame training을 사용하는 TAN을 통해 long-range temporal relation을 고려하는 모델을 만들었다는 의의가 있다.

- IDS (ID-Switch)
가장 인상깊게 보았던 부분이 IDS(ID Switch) metrics에 관한 부분이였다. ID Switch란, object 추적하는 중에 둘 이상의 object의 bounding box의 위치가 겹쳐서 둘의 id값(object 값)이 바뀌는 것을 의미한다. 이 값을 평가하는 metrics가 IDS인데, MOTR이 IDS값을 다른 모델들에 비해 크게 하락시킨 것을 볼 수 있었다.
IDS는 temporal 정보가 부족하기 때문에 나타나는 현상인데, MOTR은 전체 구조를 end-to-end로 연결하고, multi-frame TAN을 통해 이전의 frame들과 상호작용을 하여 판별하기 때문에 long-range의 temporal relation을 모델링할 수 있도록 만들어서 IDS를 줄일 주 있었다고 한다.
Video sequence는 연속적인 query passing을 얼마나 길게 수행할건지를 결정하는 length값인데, 추적할 수 있는 temporal 정보를 조절한다. Figure17에서 윗줄의 multi-frame은 video sequence=2로, 아래줄의 multi-frame은 video-sequence=2~5로 설정된 결과이고, video sequence가 길어졌을 때 temporal relation 정보가 늘어나서 IDS가 줄어든 것을 볼 수 있다.

Reference
[1] Fangao Zeng, "MOTR: End-to-End Multiple-Object Tracking with TRansformer", 2021
[2] Laura Leal-Taixé, "multiple object tracking with context awareness", 2014
'Paper Review🥔 > Video' 카테고리의 다른 글
| [포테이토 논문 리뷰] Spatiotemporal Contrastive Video Representation Learning (2) | 2022.10.06 |
|---|